Build a Flask app for model serving
01 Dec 2018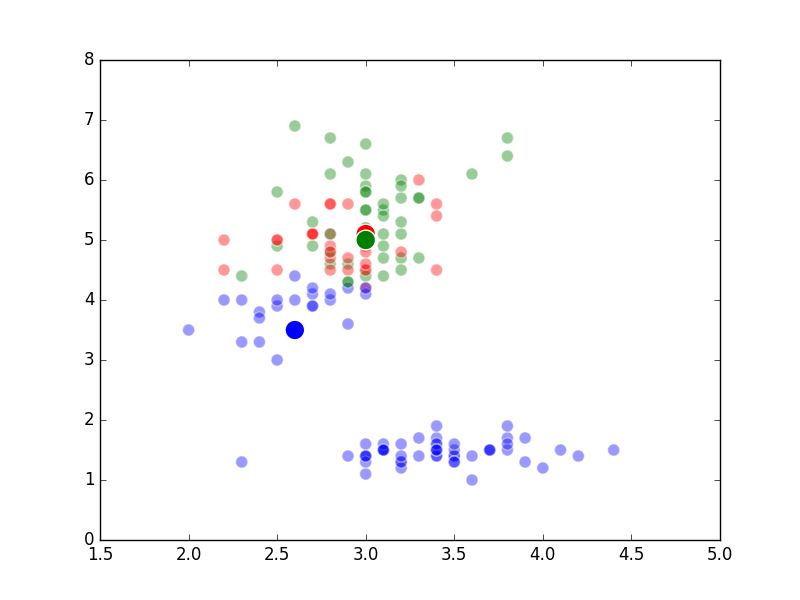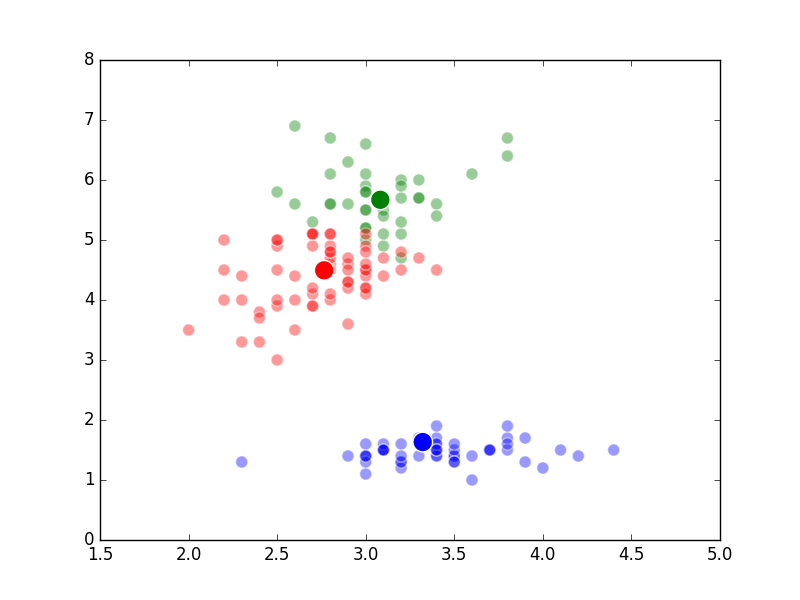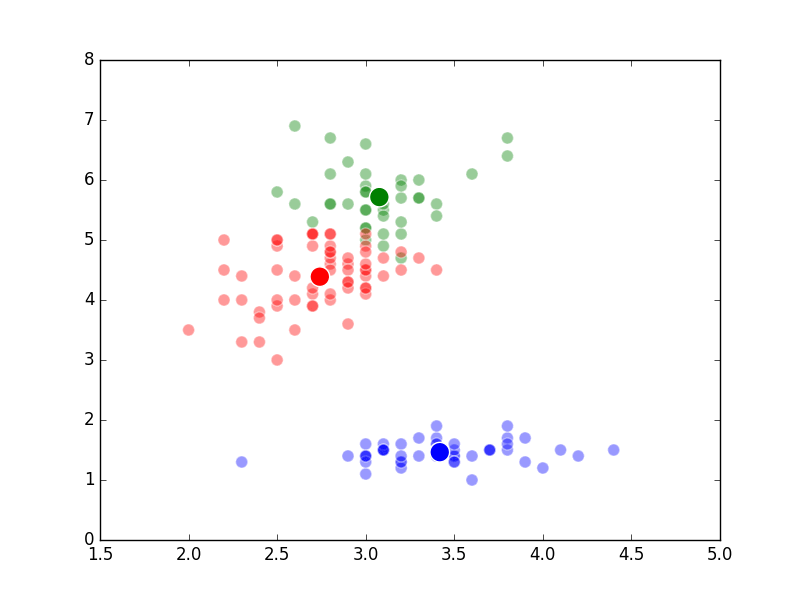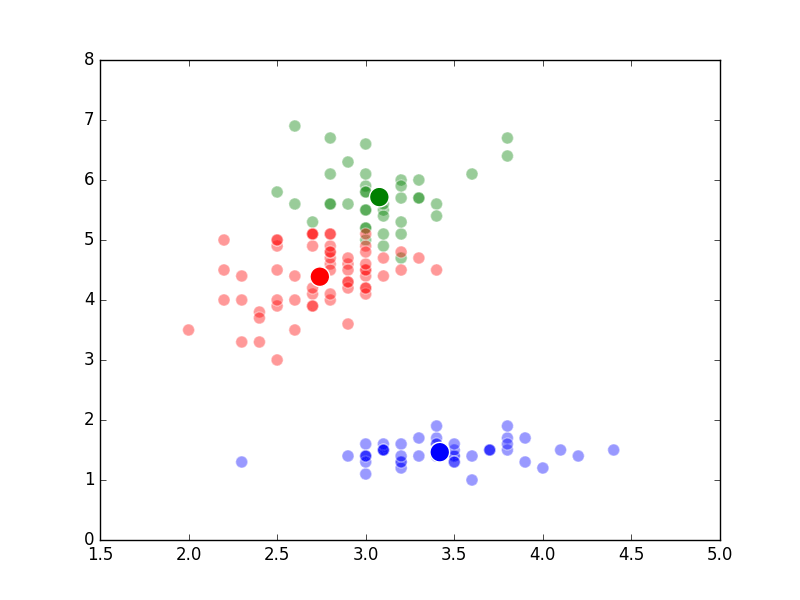
This post is modeled off a workshop I gave to the Seattle Building Intelligent Applications Meetup.
This post is modeled off a workshop I gave to the Seattle Building Intelligent Applications Meetup.
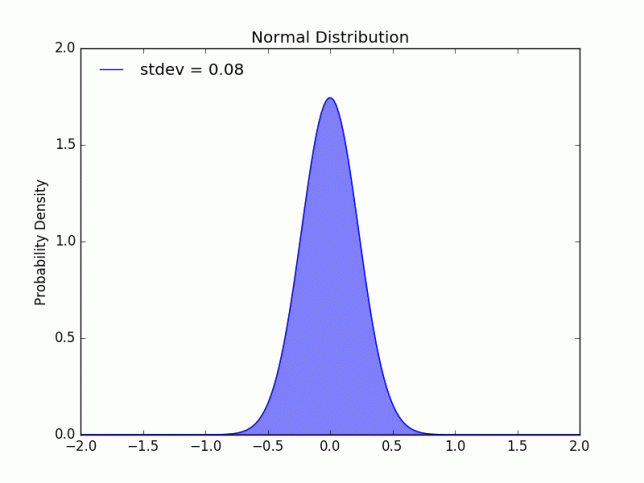
Today, the high in Seattle hit 92°F. It’s very hot in my apartment, I feel like a normal distribution with an increasing standard deviation…
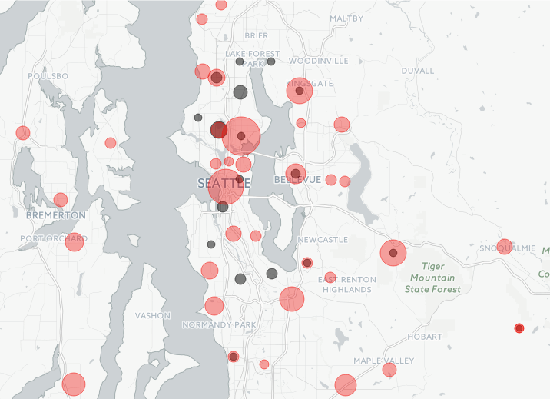
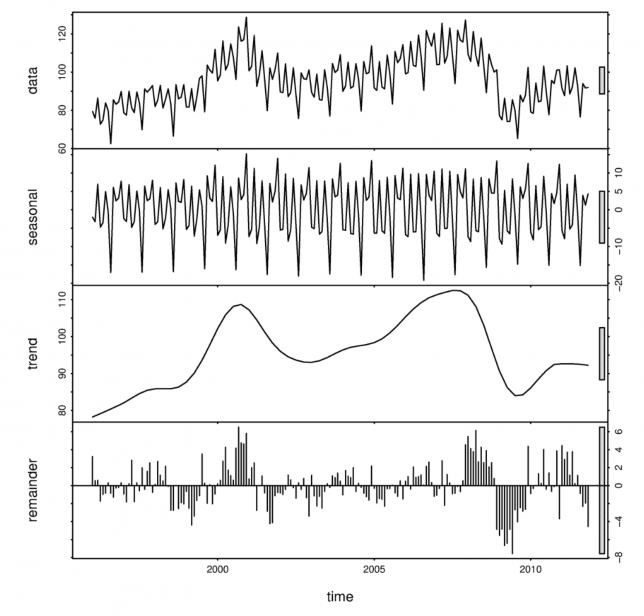
For years, the criminalization of Marijuana sale and usage has made data collection and research on the topic difficult to perform. In Washington state, Recreational Marijuana went on sale in local dispensaries starting mid-2014. The question of whether or not the opening of a dispensary produces a spike in the amount and type of Marijuana use is a valid question for legislators, administrators, doctors and more.
![[R] A little bit on multidimensional arrays and apply()](/public/img/2015/08/3d-array-apply-1.png)
The command-line can be a little unintuitive when dealing with multidimensional objects since it is a 2D medium. It is therefore hard to envision objects greater than 2-dimensions. They exist however!